选自DeepMind
作者:Adam Santoro等
机器之心编译
参与:机器之心编辑部
想象一下在阿加莎·克里斯蒂(《东方快车谋杀案》作者)的侦探小说里收集所有证据找出犯人的读者,在足球滚到河边时上前停球的小孩,甚至一个购物者在购买水果时比较猕猴桃和芒果的优点。
人类将这个世界理解为事物之间的关系。我们了解世界运行的方式,因为我们能对不同事物之间的联系做出逻辑推理——物理对象、语句,甚至抽象的想法。这种能力被称为关系推理,它是人类智能的核心。
我们以每天所有感官接收到的非结构化信息为基础构建这种关系。我们的眼睛会接收到大量光线,而我们的大脑会将这些「巨量嘈杂的混乱」组织到我们需要关联的特定实体之中。
这两篇论文都展示了有望理解关系推理这一挑战的新方法。
开发具有人类级别灵活性和效率的人工智能系统需要实现人类级别的认知能力,这意味着它们必须能从非结构化数据中推理实体并认识其中的关系。解决这个问题意味着系统可以将有限技能推广到无限的新任务中,从而展示出强大的能力。
现代深度学习方法在解决非结构性数据问题的过程中已经有了很大进展,但此前的诸多方法忽略了考虑事物之间的联系。
在 DeepMind 最近发表的两篇论文中,研究人员探索了深度神经网络对非结构化数据执行复杂关系推理的能力。第一篇论文《A simple neural network module for relational reasoning》中,DeepMind 描述了 Relation Network(RN),并表明它在一种高难度任务中具有超越人类的表现;而在第二篇论文《Visual Interaction Networks》中,研究者们描述了一种通用模型,它可以纯粹基于视觉观察结果来预测物理对象的未来状态。
一种用于关系推理的简单神经网络模块
为了更深入地探索关系推理的思想,并测试这种能力能否轻松加入目前已有的系统,DeepMind 的研究者们开发了一种简单、即插即用的 RN 模块,它可以加载到目前已有的神经网络架构中。具备 RN 模块的神经网络具有处理非结构化输入的能力(如一张图片或一组语句),同时推理出事物其后隐藏的关系。
使用 RN 的网络可以处理桌子上的各种形状(球体、立方体等)物体组成的场景。为了理解这些物体之间的关系(如球体的体积大于立方体),神经网络必须从图像中解析非结构化的像素流,找出哪些数据代表物体。在训练时,没有人明确告诉网络哪些是真正的物体,它必须自己试图理解,并将这些物体识别为不同类别(如球体和立方体),随后通过 RN 模块对它们进行比较并建立「关系」(如球体大于立方体)。这些关系不是硬编码的,而是必须由 RN 学习——这一模块会比较所有可能性。最后,系统将所有这些关系相加,以产生场景中对所有形状对的输出。
研究人员让这一新模型处理了各种任务,其中包括 CLEVR——一个视觉问答任务集,旨在探索神经网络模型执行不同类型推理的能力,如计数、比较和查询。CLEVR 由以下这样的图片组成:

对于每个图片,都有与图中物体相关的问题。例如,对于上图的问题可能是:「在图中有一个小的橡胶物体和大个的圆筒形有相同的颜色,那么它是什么形状的?」
目前的机器学习系统在 CLEVR 上标准问题架构上的回答成功率为 68.5%,而人类的准确率为 92.5%。但是使用了 RN 增强的神经网络,DeepMind 展示了超越人类表现的 95.5% 的准确率。
为了测试 RN 的多任务适用性,研究人员还在另一个大不相同的语言任务中测试了 RN 的能力。DeepMind 使用 bAbI——Facebook 推出的基于文本的问答任务集。bAbI 由一些故事组成,这些故事由数量不一的句子组成,最终引向一个问题。如:「Sandra 捡起了足球」、「Sandra 进了办公室」可能会带来问题「足球在哪里?」(答案是:办公室)。
RN 增强网络在 20 个 bAbI 任务中的 18 个上得分超过 95%,与现有的最先进的模型相当。值得注意的是,具有 RN 模块的模型在某些任务上的得分具有优势(如归纳类问题),而已有模型则表现不佳。
详细的测试结果请参阅论文《A simple neural network module for relational reasoning》。
视觉交互网络(VIN)
这是在物理场景中进行预测的另一个关键的关系推理。人类在看过一眼之后就能推断一个物体是什么,接下来数秒会发生什么。例如,如果你向墙上踢足球,大脑就会预测撞击之后球会发生什么,而后球的运动轨迹是什么(球会以一定的速度比例撞向墙面,而墙纹丝不动)。
这些预测都受到复杂的推理认知系统的影响,从而对物体以及相关的物理作用进行预测。
在 DeepMind 开发「视觉交互网络(VIN,一种模拟这种能力的模型)」的相关工作中,VIN 能够只从几个视频画面中推理多个物体的状态,然后使用状态关系预测未来物体的位置。它不同于生成式模型。生成式模型可能视觉地「想象」接下来的视频画面,但 VIN 是预测关联物体间的潜在关系状态。
VIN 动态预测(右)与真值模拟(左)的对比。VIN 接受 6 帧画面的输入之后,能够预测 200 帧。大约 150 帧内,VIN 的预测近似于真值模拟。之后虽然有所不同,但依然能产生看上去合理的动态预测。
VIN 包括两种机制:视觉模块和物理推理模块。二者结合能够将视觉场景处理成一系列有区别的物体,并学习物理规则的一套隐式系统,从而预测未来物体会发生什么。
研究人员在多种系统中测试了 VIN 的能力,包括桌球撞击、行星系统的引力关系等。结果显示 VIN 能够准确预测物体在未来数百步发生的事。
在与之前公开的 VIN 模型、 变体(其中关系推理的机制被移除了)的实验对比中,完整 VIN 的表现要好很多。
详细的细节可查看下面的第二篇论文。
总结
DeepMind 的两篇论文都展现出了理解关系推理难题的有潜力的方法。通过将世界万物分解成物体以及之间的关系,它们展现了神经网络可具备的强大的推理能力,让神经网络能够对物体进行新的场景结合。表面上看起来不同但本质上有共同的关系。
研究人员认为,这些方法有足够的延展性,可被用于许多任务,帮助人们建立更复杂的推理模型,让我们更好地理解人类强大的、灵活的通用智能中的关键成分。
论文一:一种用于关系推理的简单神经网络模块(A simple neural network module for relational reasoning)

论文地址:https://arxiv.org/abs/1706.01427
关系推理(relational reasoning)是通用智能行为的核心组成部分,但神经网络却难以学习到这种能力。在这篇论文中,我们描述了可以如何使用关系网络(RN/Relation Networks)作为简单的即插即用模块来解决那些从根本上取决于关系推理的问题。我们在三种任务对使用 RN 增强的网络进行了测试,分别是视觉问答(使用了一个难度很大的数据集 CLEVR,我们实现了当前最佳且超过人类水平的表现)、基于文本的问答(使用了 bAbI 任务套件)和关于动态物理系统的复杂推理。然后,使用一个被精心调节过的数据集 Sort-of-CLEVR,我们表明强大的卷积网络不具备解决关系问题的通用能力,但可以通过使用 RN 增强而获得这种能力。我们的研究表明了装备了 RN 模块的深度学习架构可以如何隐含地发现和学习推理实体以及它们的关系。
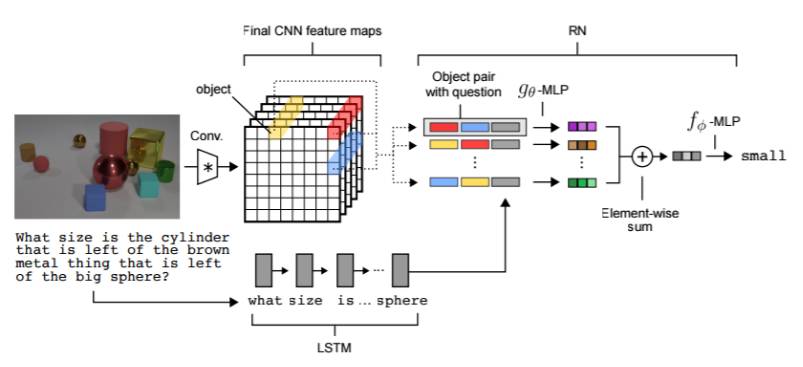
图 2:视觉问答架构。问题在经过 LSTM 处理后产生一个问题嵌入(question embedding),而图像被一个 CNN 处理后产生一组可用于 RN 的物体。物体(图中用黄色、红色和蓝色表示)是在卷积处理后的图像上使用特征图向量构建的。该 RN 网络会根据问题嵌入来考虑所有物体对之间的关系,然后会整合所有这些关系来回答问题。
论文二:视觉交互网络(Visual Interaction Networks)

论文地址:https://arxiv.org/abs/1706.01433
人类只需简单一瞥就能给出许多类型物理系统的未来状态的丰富预测。另一方面,来自工程学、机器人学和图形学的现代方法则往往受限于狭窄的领域,且需要对当前状态的直接观测。我们引入了视觉交互网络(Visual Interaction Network),这是一种用于从原始视觉观察中学习物理系统的动态的通用模型。我们的模型由一个基于卷积神经网络的感知前端(perceptual front-end)和一个基于交互网络的动态预测器(dynamics predictor)组成。通过联合训练,这个感知前端可以学会将一个动态视觉场景解析成一组有系数的隐含物体表征(factored latent object representations)。而其动态预测器则可以通过计算它们的交互和动态来这些状态的未来情况,从而预测出一个任意长度的物理轨迹。我们发现,仅需要 6 个输入视频帧,该视觉交互网络就可以生成精准的未来轨迹,且这些轨迹的时间步数都是数以百计的,可涵盖大量的物理系统。我们的模型也可以被应用于带有不可见物体的场景,基于它们对可见物体的影响效果来推理它们的未来状态,而且还可以隐含地推断出物体的未知质量。我们的结果表明这种感知模块和基于物体的动态预测器模块可以归纳有系数的隐含表示(factored latent representations),其可以支持准确的动态预测。这项成果为根据复杂物理环境中的原始感官观察而进行的基于模型的决策和规划(model-based decision-making and planning)开启了新的机会。
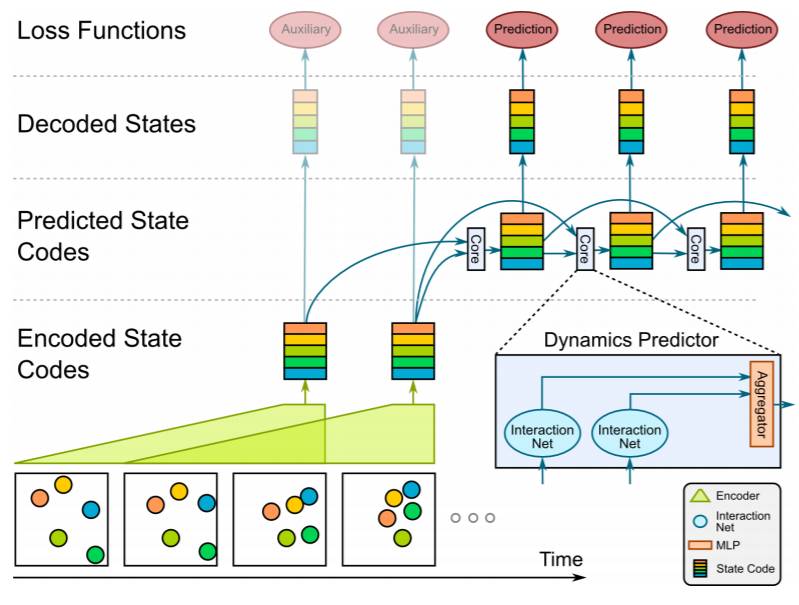
图 1:视觉交互网络:这里描述了一般架构(说明见右下角)。其中视觉编码器以连续帧的三元组为输入,并为每个三元组中的三帧输出一个状态码。该视觉编码器在输入序列上以一种滑动窗口的形式工作,然后得出一个状态码序列。应用于该编码器的解码后的输出上的辅助损失(auxiliary losses)有助于训练。然后该状态码序列被馈送入动态预测器,其包含多个交互网络内核(本例子中是 2 个),这些内核工作在不同的时间偏移(temporal offsets)上。然后这些交互网络的输出被送入一个聚合器(aggregator),以得到下一个时间步的预测。这个内核以一种滑动窗口的形式工作,如图所示。其预测的状态码是线性编码的,然后在训练时被用在预测损失中。
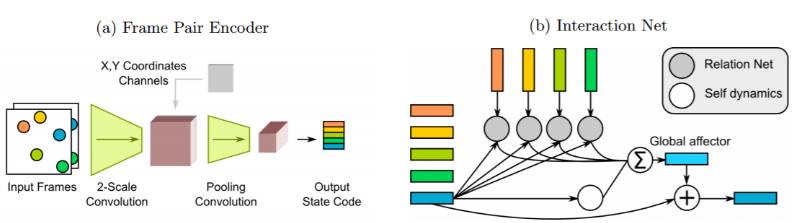
图 2:帧配对编码器(Frame Pair Encoder)和交互网络(Interaction Net)。(a)Frame Pair Encoder 是一个 CNN 网络,可将两个连续输入帧转换为一个状态码。在池化(pooling)处理成单位宽度和单位长度之前,重要特征要与 x,y 坐标轴相关联。池化后的输出被重塑成一个状态码。(b) 通过动态预测器的处理,交互网络(IN)可以被应用到每一个时间偏移当中。每一个 slot 都有相应的关系网络,这可以使每个 slot 都和其他 slot 相互关联。而且每一个 slot 本身又都应用了一个自动态网络(self-dynamics net)。这两种输出结果通过变换器(affector)被累加求和,并且进行后期处理(post-processed),从而预测出新的 slot。
原文地址:https://deepmind.com/blog/neural-approach-relational-reasoning/
更多有关GMIS 2017大会的内容,请点击「阅读原文」查看机器之心官网↓↓↓
