新智元推荐
来源:微软研究院AI头条授权转载
演讲:童欣
新智元启动新一轮大招聘:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。
简历投递:jobs@aiera.com.cn
HR 微信:13552313024
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。
加盟新智元,与人工智能业界领袖携手改变世界。
【新智元导读】微软亚洲研究院网络图形组首席研究员童欣,日前在微软亚洲研究院“让世界充满AI:人工智能研讨会”发表演讲《网络图形:从交互到智能》。童欣回顾了他所在的互联网图形组过去几年的研究项目及成果,总结认为智能算法也许是实现普通用户产生三维内容的一个最终解决方案。最后,童欣分享了“三个D”的经验:Open-minded,积极借鉴其他领域方法;Concentrated,聚焦自己的问题;End to end,解决用户实际问题。

“MSRA 十年纪念时,我希望自己的图形梦一直做下去。” 童欣告诉新智元:“现在,我希望能帮每个人实现他们的图形梦!” 上图为微软亚洲研究院(MSRA)成立十周年照相留念,便签上的字 “十年一觉图形梦,愿 MSRA 成为所有人的梦工厂”。
【人物简介】童欣,1999年毕业直接加入微软亚洲研究院,目前担任微软亚洲研究院网络图形组首席研究员,主要研究方向为计算机图形学和计算机视觉。
童欣:几天前我得到通知要在这里做一个报告,我非常焦虑和紧张。上次这么紧张还是第一次在SIGGRAPH报告论文的时候。我想了很久,决定了这个题目,“网络图形:从交互到智能”,我想把过去几年来的一些想法作一个思想汇报,请各位院友指正、批评、提出建议。
事情要从15年前说起,2001年的时候,Harry(沈向洋)和百宁(郭百宁)决定要成立一个新的图形组,那么就需要有一个很酷的组名,于是他们决定叫做“互联网图形组”。名字起得很好,问题也马上来了:基本上每个见到我们的人都问什么是 Internet Graphics。为了回答这个问题,在2001年的时候我们集中全组的力量做了第一个项目,Game Download & Play,这项目我们想把游戏图形的数据、几何、纹理做一些压缩,通过互联网下载的时候,大家就不用等那么长的下载时间了,很快把一部分数据下载到本地之后,大家就可以开始玩游戏了。这项目可以说非常成功。这之后我们顺利地开始做 SIGGRAPH……转眼到了2010年,百宁把接力棒交给我,让我慢慢开始负责整个图形组,那么我要怎样激励大家、我们组里应该有什么样的愿景。我也开始思考这些问题,重新在问自己到底什么是互联网图形?

如果我们看看周围,可以看到很多成功的例子。互联网加文字,有网络文学、微博,维基百科。加图片就有美图秀秀、Instgram等等。互联网加视频也很好,有Youtube、爱奇艺等很多国内网站,还有网络直播,还有了网红。回头再看看Graphics,却好像什么都没发生,就这样过了十年,那么到底出了什么问题呢?——有传言说,如果你站在风口,就算你是一头猪也能飞起来。可是我这么瘦的一个人,站了这么久,怎么还没飞起来,这到底出了什么问题?
我做了一些粗浅的研究,认真想了一想。我发现,飞起来这件事,不是什么都可以,要满足两个条件:第一,要Everyone,就是内容最好是每一个人都能产生、都能创造,那么有了网络大家就可以互相交流,你的内容就会有海量增长。第二,要Everywhere,随着移动平台的发展,如果你这个内容的产生和消费能互联到每一个平台上,让大家在任何地方都能生产消费,这时候你就真的飞起来了。
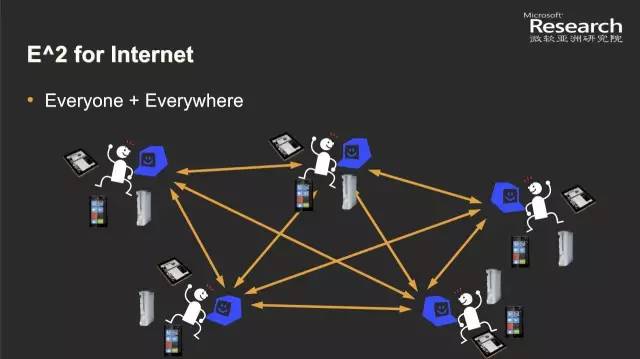
那么我们看看图形学到底是个什么状况?答案很悲惨:在Everyone方面,三维内容的生产,对普通用户而言还是非常难的任务。最左边大家可以看到传统的造型动画软件,界面很复杂,即使是艺术家也需要好几年的学习才能做好一个模型。另一方面,虽然我们有一些设备帮助大家来做三维内容的捕捉,比如三维扫描仪、光穹、动捕等等,但这些设备都非常昂贵,每个要几百万,还需要专门的场地和专业的操作,普通用户享受不到。


我们再看看Everywhere,发展了这么多年,所有三维图形的内容都是通过一个二维的屏幕来传递给大家的——某种意义上来讲,我们的内容和2D的视频就没有太大的区别。我们的交互就不用提了,我们还得通过鼠标、键盘或者gamepad进行交互,这些交互跟我们在真实三维世界中所做的交互是非常不同的。由于这些限制,大家就会发现,到现在为止,图形的生产和消费基本和互联网无关,基本的方式还是少数的艺术家,他们组织在一起,经过艰苦的奋斗,做了一些游戏、电影,然后把东西通过市场分发给成千上万的消费者进行消费。一切还是停留在传统的模式。

基于这样的想法,我们就提出了我们互联网图形组的愿景,这就是,我们希望做一些图形学的工具和系统,能帮助每个人很方便地产生、观看和分享一些三维内容。同时,我们希望能在自然世界和虚拟世界间提供更自然的界面和交互的方式,另外我们还想在可视的和不可视的抽象信息之间提供一些自然的界面,把抽象的信息变成可视的展现出来。

过去五年我们为了这一愿景做了很多不同方面的研究,慢慢意识到也许基于智能或者数据的方法是个很好的解决方案。原因有下面几个:第一,我们已经有了一些昂贵的设备,这些设备帮助我们捕捉了大量高质量的数据。第二,我们也有了比较便宜的设备,这些设备可以为我们的系统提供一个初始的输入,不用从零开始了。最后,是一些关于机器学习方面的技术进展可以让我们把这些技术用到图形学的问题里。

那么也许一个比较好的解决方案是通过低价普及的设备,比如普通相机和深度相机,加上智能的算法,再有些时候需要一些简单的用户输入,来方便地产生三维的内容。关于智能算法,我们希望它能做两件事,一是希望能够利用到所有三维数据的本征特性,用这些帮助我们产生内容; 二是可以用机器学习来进行端到端的学习,在输入和输出之间直接建立一些联系。
下面我用我们组研究的一个研究课题三维物体的数字化来进一步说明举例。
三维物体数字化的目标是希望将一个真实世界的三维物体,完美地传递扫描进一个虚拟世界。为做到这一点,我们不仅仅要捕捉三维物体的几何形状,还要重现它的材质信息。注意,有了几何信息虽然可以知道物体形状,却不知道这个物体是什么,只有有了物体材质表面反射属性以后,我们才能在三维世界中真正栩栩如生地体现出来,大家就会的清楚知道这是真实世界的一个啤酒瓶,上面有一个纸标签,标签上有烫金字……我想我不需要再说明这样一个工具对VR/AR内容的产生、或者对虚拟购物等应用是多么重要。

那么我们看看现在的解决方案是什么。基本上我们可以发现这流水线还是非常长的,首先用设备扫描三维几何形状,但是扫描得到的这些几何形状在大部分情况下非常糟糕,需要大量人工交互工作来去除噪声、平滑三维模型。材质捕捉就更麻烦了,我们需要把物体挪到专用的捕捉室,放在专用的设备上,捕捉物体在各种光照、各种视点下的外观,有了这些才能采集出真正的物体形状和材质。大家可以发现这样一个基本的任务还是有很多障碍,首先去噪方面需要很多手工交互工作,其次材质捕捉设备很昂贵,另外这个流水线很长,需要分开的步骤去先捕捉几何,再用另外的设备捕捉材质。
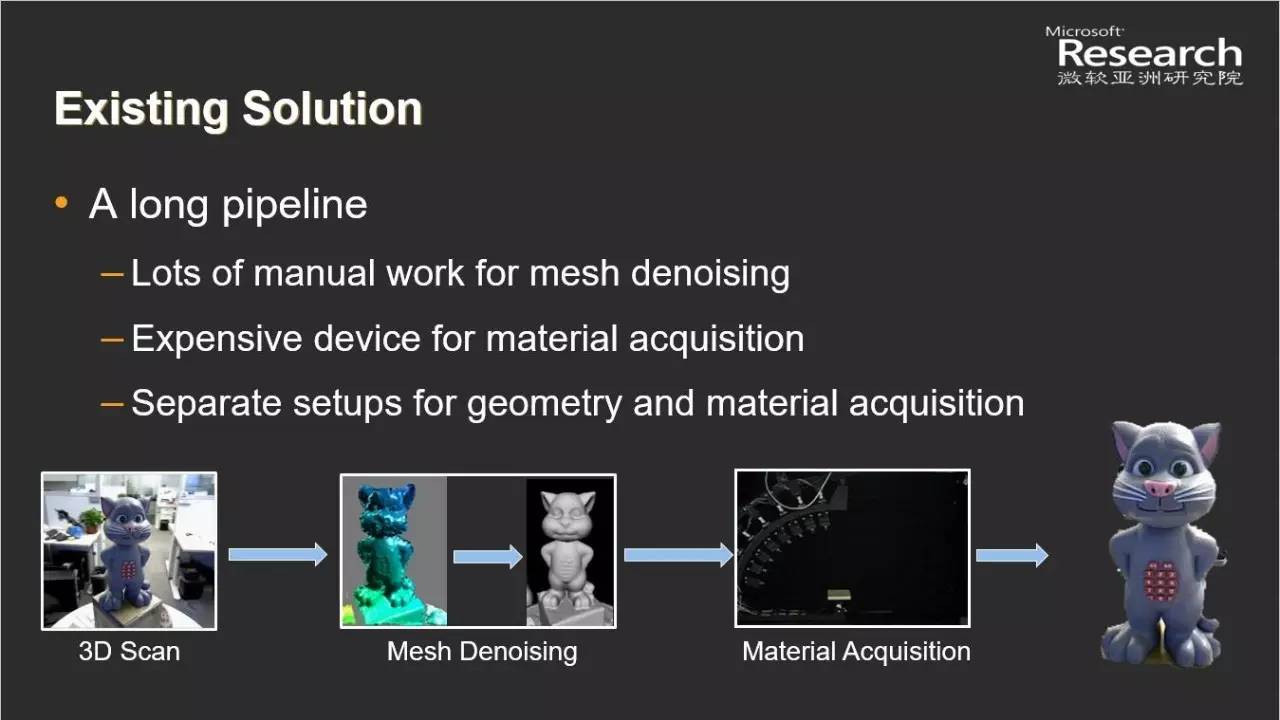
那么我们看看用一些智能的算法能帮我们做什么事情:第一个要介绍给大家的是我们去年研发出来的一个数据驱动的模型去噪算法。这里要做的是希望有个自动的算法,帮我们除去扫描模型上的噪音,同时保留模型上面所有的几何细节,并且算法对不同设备扫描出来的模型都能很好的处理。我们的算法通过收集带噪声的扫描模型和对应的基本没有噪声的高质量模型,先去学习训练这些几何之间的对应关系。基于这个对应关系,我们就可以将一个带有噪声的扫描模型直接对应生成它的没有噪声的模型,从而实现去噪的效果。这是我们组的刘洋研究员带领实习生完成的工作。

我们这个算法在训练好了以后,用户在用的时候是全自动的。更了不起的是,我们的算法在我们所有的测试模型上去噪效果都超过了所有目前已有的模型去噪算法。同时我们的算法还比所有已知算法都要快。我们很快会把我们的算法源代码和数据公布在网上,希望其他研究人员都可以在基础上继续研究,同时很多用户也可以直接使用我们的算法。
下面我们来看一些实验结果。左边是输入一个扫描模型,有很多的噪声,右边是Ground Truth,右边第二个是我们算法得到的结果。
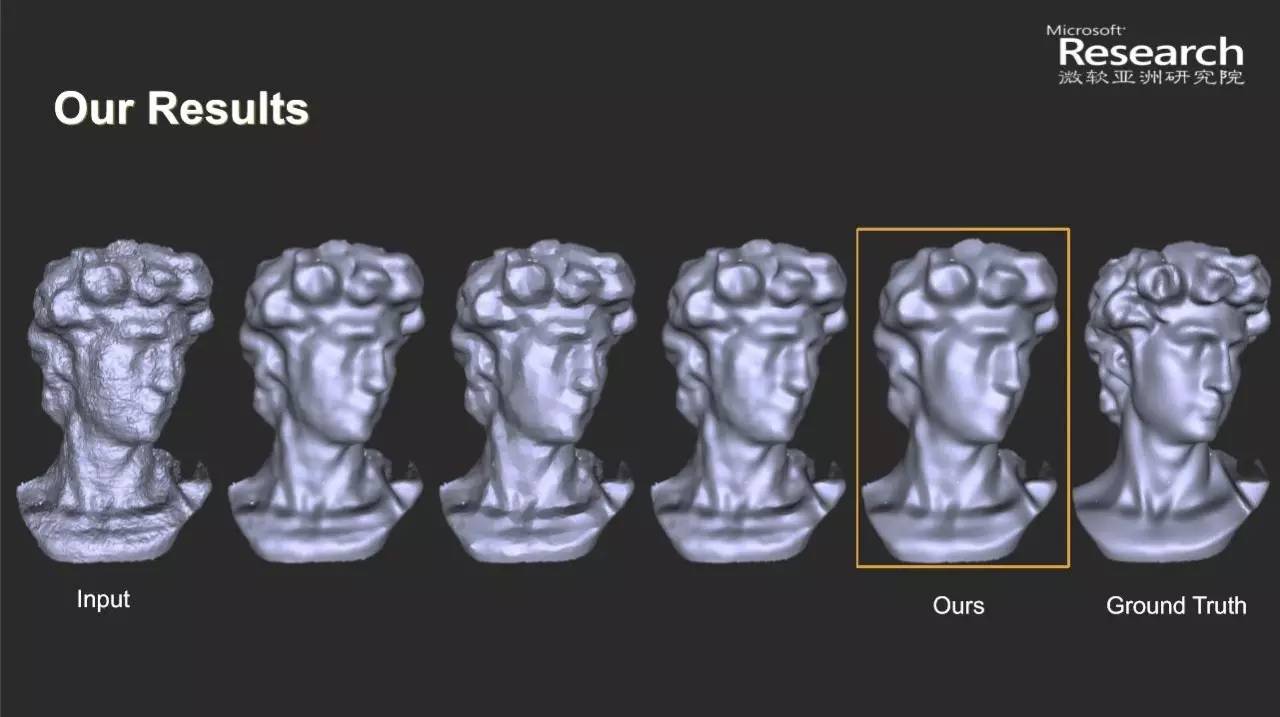
这是另一个例子,扫描模型的噪音非常大,以前的算法只能除掉一些噪音,或者会抹去很多模型上的集合细节。我们的算法可以比较好地去掉模型上的噪声,同时比较好地保留它的几何细节。

我们再看看材质捕捉方面,刚才我们说材质捕捉设备很昂贵,捕捉过程很麻烦。有什么更好的做法来做呢?我们在两年前做了世界上第一个不需要任何特殊设备和光照,只从自然未知光照下拍摄的物体视频出发进行材质捕捉的算法。这是我们团队的董悦研究员带领实习生完成的工作。输入就是大家看到的左边的视频序列,右边是输出的材质捕捉的结果,最后我们把它放在一个新的光照下,物体可以栩栩如生地再现出来。

这个算法的关键是我们要从视频中同时估计物体的光照和材质属性。我们发现自然环境中的光照和材质本身具有不同的属性,可以用这些属性很巧妙地从观察的数据最终把二者分分离开来。
这里显示了我们算法所恢复的物体的材质效果,不论是啤酒瓶上印刷的标签,还是光滑的瓷器,还是带有铁锈的金属,我们的算法都能自动地从一些视频序列中把高质量的材质重构出来。

有了这些工作,上面的流水线变得简单自动了很多,但还是要经过两步。有没有可能一步就把所有事情搞定?去年我们在这方面做了一些研究,做了世界上第一个从视频中同时恢复物体的几何形状和表面材质的算法。这个方法只是用了视频而不再需要任何的深度相机捕捉的数据。同样,我们的算法不需要知道光照信息。左边是我们算法输入的视频,右边是捕捉的物体和材质在新的光照环境下绘制的结果。

这是我们捕捉到的几何和材质和真实照片的对比,你可以看到所有的几何细节、表面反光和材质属性都被很好的重建出来了。在不同的光照下看,所有物体都像真实物体一样得到真实再现。

基于这一结果,我们把做的结果放到HoloLens,并和我们周围的真实光照结合在一起,可以生成非常真实的效果。

刚才我们以物体的数字化为例说明了如何采用智能的算法帮助我们简化建模过程,方便普通用户捕捉三维内容。总结一下,在过去几年中我们在智能算法方面做了很多努力,我们逐渐认识到,智能算法也许是能够实现普通用户产生三维内容的一个最终解决方案。
最后,我也想分享一下我在这个过程中所得到的经验或者教训:我总结为三个D。首先是Open-minded。我们要积极地学习借鉴其他领域的方法算法,比如我刚才讲的去噪算法,就是从孙剑和周昆他们做人脸跟踪那里学习的算法。而我们所做的材质捕捉的算法,是从视觉里面的图像防抖算法里得到的启发。现在我们也在学习和深度学习相关的东西。第二是 Concentrated。第一条就像吸星大法,把别人的东西都吸过来了,但还不够,还要易筋经,把东西化成自己的,要知道自己拿到这个工具是要解决自己的问题的,聚焦于自己的问题,把那些东西为你所用。最后是End to end,我们并不想发了一篇论文然后研究就结束了,论文更多的是一个交流表达的手段,关键是把问题真正给解决掉,最后给用户提供一个真正的端到端的解决方案。
展望未来,可以说我们才刚刚起步,前面还有很长的路要走。这也许是个坏消息,但对我来说这其实也是好消息。因为这意味着前面还有很多不确定性、很多挑战。作为一个研究人员来说,这些困难、挑战也正是我们最终的乐趣所在,虽千万人,吾往矣。
谢谢大家。

新智元启动新一轮大招聘:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。
简历投递:jobs@aiera.com.cn
HR 微信:13552313024
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。
加盟新智元,与人工智能业界领袖携手改变世界。
