选自Github
机器之心编译
参与:吴攀
在「非法」查看色情视频时,你是否也为其「漫长」的铺垫和前奏感到懊恼呢?前几天,GitHub 用户 ryanjay0 开源了一个可以用来识别色情视频中特定类型的场景的人工智能项目 Miles Deep。该算法可以将你想看的类型的片段从完整视频中截取出来并生成一个集合了这些片段的新视频,让你可以不再为那些多余的片段烦恼。
Miles Deep 使用了一个带有残差连接(residual connections)的深度卷积神经网络(DCNN),可以基于性行为(sexual act)将一段色情视频的每一秒分类成 6 种类别,其准确度高达 95%。然后它可以使用这种分类来自动编辑该视频。它可以移除所有不包含性接触的场景,或者编辑去掉一种特定的性行为。
Miles Deep 和雅虎最近发布的 NSFW 模型(见机器之心报道《雅虎开源首个色情图像检测深度学习解决方案》)使用了类似的架构,但不一样的是 Miles Deep 还能够区分裸体和多种特定的性行为之间的不同。就我所知,这是第一个公开的色情视频分类或编辑工具。
这个程序可以说是使用 Caffe 模型进行视频分类的一种通用框架,其使用了 C++ 的 batching 和 threading。通过替换权重、模型定义和 mean file,它可以立即被用于编辑其它类型的视频,而不需要重新编译。下面会介绍一个例子。
安装
Ubuntu 安装(16.04)
依赖包(Dependencies)
sudo apt install ffmpeg libopenblas-base libhdf5-serial-dev libgoogle-glog-dev
额外的 14.04 依赖包
sudo apt install libgflags-dev
CUDA(推荐)
如果要使用 GPU,你需要 Nvidia GPU 和 CUDA 8.0 驱动。强烈推荐;可提速 10 倍以上。这可以通过软件包安装或直接从 NVIDIA 下载:https://developer.nvidia.com/cuda-downloads
CUDNN(可选)
这是来自 NVIDIA 的额外的驱动,可以让 CUDA GPU 支持更快。在这里下载(需要注册):https://developer.nvidia.com/cudnn
下载 Miles Deep
miles-deep (GPU + CuDNN)
miles-deep (GPU)
miles-deep (CPU)
也要下载这个模型。将 miles-deep 与该模型的文件夹放在同一个位置(而不是在模型文件里面)。
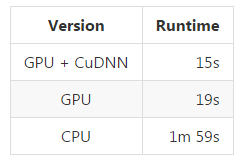
注:是在一个 GTX 960 4GB 上测试了一段 24.5 分钟长的视频
Windows 和 OSX
我目前还在开发用于 Windows 的版本。但我没有 Mac,不过应该只需要做一些小修改就可以在 OSX 上运行。编译指令如下。https://github.com/ryanjay0/miles-deep#compiling
使用方法
例子:
miles-deep -t sex_back,sex_front movie.mp4
这能找到后向和前向的性爱(sex from the back or front)场景,并输出结果到 movie.cut.avi
例子:
miles-deep -x movie.avi
这能编辑去除 movie.avi 中所有的非性爱场景,并将结果输出到 movie.cut.avi。
例子:
miles-deep -b 16 -t cunnilingus -o /cut_movies movie.mkv
这能将批大小(batch size)减小到 16(默认为 32)。筛选出舔阴(cunnilingus)的场景,结果输出到 /cut_movies/movie.cut.mkv
注:如果你的内存不够,可以减小批大小
在多种批大小情况下的 GPU VRAM 用量和运行时间:
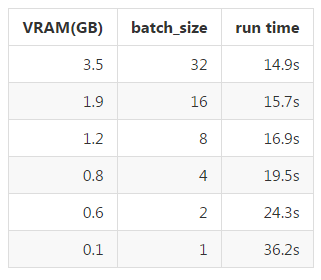
该结果是在带有 4GB VRAM 的 Nvidia GTX 960 上测试得到的,样本是一段 24.5 分钟的视频文件。当 batch_size = 32 时,处理 1 分钟的输入视频大约需要 0.6 秒,也就是说每小时大约 36 秒。
除了 batching 之外,Miles Deep 还使用了 threading,这让其可以在分类的过程中截取和处理截图(screenshot)。
预测权重
这里是一个预测一段视频中每一秒的例子:
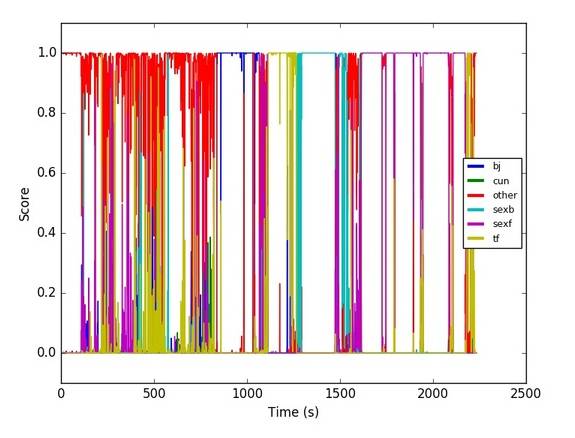
通过你自己的 Caffe 模型使用 Miles Deep
找猫
下面这个例子是如果通过你自己的模型(或一个预训练的模型)使用这个程序:
MODEL_PATH=/models/bvlc_reference_caffenet/
miles-deep -t n02123045 \
-p caffe/${MODEL_PATH}/deploy.prototxt \
-m caffe/data/ilsvrc12/imagenet_mean.binaryproto \
-w caffe/${MODEL_PATH/bvlc_reference_caffenet.caffemodel \ -l caffe/data/ilsvrc12/synsets.txt \ movie.mp4
这能找到在 movie.mp4 中的所有带有虎斑猫(tabby cat)的场景,并返回仅带有这些部分的结果 movie.cut.mp4。
代码中的 n02123045 是虎斑猫的类别。你可以在 caffe/data/ilsvrc12/synset_words.txt 查找这些类别的代码。你也可以使用一个来自 model zoo 的预训练的模型:https://github.com/BVLC/caffe/wiki/Model-Zoo
注:这个例子只是展示了其中的句法。但不知怎的,在我的经历中它的表现很差,很可能是因为分类有 1000 个。这个程序也能完美适合带有一个「other」类别的分类数量更小的模型。
模型
该模型是一个用 pynetbuilder 创建的带有残差连接(residual connections)的卷积神经网络(CNN)。这些模型都是 ImageNet 上预训练的。然后其最终层经过调整以适应新的分类数量和微调(fine-tuned)。
正如 Karpathy et al 的论文《Large-scale Video Classification with Convolutional Neural Networks》建议的那样,我训练了最上面 3 层的权重而不只是最顶层的,这稍微提升了一些准确度:

下面使用不同的模型微调最上面 3 层所得到的结果,该结果是在 2500 张训练图像上测试得到的,这些图像来自与训练集不同的视频。
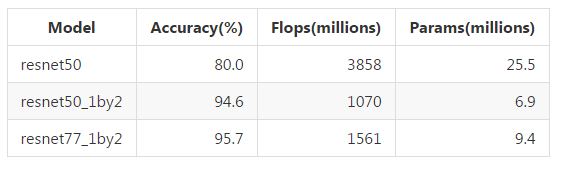
训练损失和测试精度:
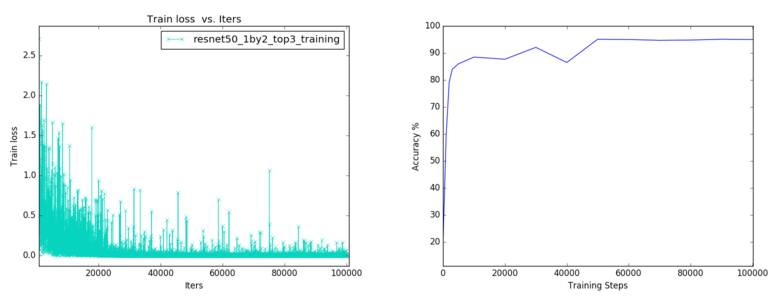
在所有测试的模型中,resnet50_1by2 在运行时间、内存和准确度上表现出了最佳的平衡。我认为全 resnet50 的低精度是因为过拟合(overfitting)的关系,因为它有更多的参数,也许其训练可以按不同的方式完成。
上面的结果是通过 mirroring 而非 cropping 得到的。使用 cropping 能够将在 resnet50_1by2 上的结果稍微提升至 95.2%,因此它被用作了最终的模型。
使用 TensorFlow 微调(fine-tuning)Inception V3 也能实现 80% 的准确度。但是,这是使用 299x299 的图像大小,而不是 224x224 的大小,也没有 mirroring 或 cropping,所以它们的结果不能直接进行比较。这个模型可能也会有过拟合的问题。
编辑电影
给定对于每一秒的帧的预测,它会获取这些预测的 argmax(最大值参数)并创建这段影片的截断块(cut blocks),其中的 argmax 等于目标(target),而其分数(score)也比一些阈值要大。其中的差距大小、匹配每个模块中目标的帧的最小比例(minimum fraction)和分数阈值(score threshold)都是可以调整的。FFmpeg 支持很多编解码器(codecs),包括 mp4、avi、flv、mkv、wmv 等等。
单帧 vs 多帧
这个模型并不使用任何时间信息,因为它分别处理每一张图像。Karpathy et al 的论文表明其它使用多帧(multiple frames)的模型的表现并不会好很多。它们难以应对相机的移动。将它们的慢融合模型(slow fusion model)与这里的结果进行比较仍然是很有趣的。
数据
其训练数据库包含了 36,000(和 2500 测试图像)张图像,分成了 6 个类别:
blowjob_handjob
cunnilingus
other
sex_back
sex_front
titfuck
这些图像的大小都调整为了 256x256,并且带有水平镜像(horizontal mirroring),并且为了数据增强(data augmentation)还随机剪切(cropping)成了 224×224 的大小。有很多实验没有剪切,但这能稍微提升 resnet50_1by2 的结果。
目前来说,这个数据集还受限于两个异性恋表演者。但鉴于这种方法的成功,我计划扩大分类的数量。因为这些训练很敏感,我个人并不会放出这些数据库;而只会提供训练出来的模型。
前向和后向性爱
这里的前向和后向性爱(sex front and back)是由相机的位置决定的,而非表演者的方向。如果女性表演者的身体面向相机,那么性器官的前面就展示了出来,这就是前向性爱(sex front)。如果女性的后面被展示了出来,就是后向性爱(sex back)。这创造了两种在视觉上不同的分类。其中在性交和肛交之间不做区分;前向性爱和后向性爱可能两者都包含。
编译
克隆包含 Caffe 作为外部依赖包的 git repository
按步骤指令(http://caffe.berkeleyvision.org/installation.html)安装 Caffe 依赖包以用于你的平台。Ubuntu 指令(http://caffe.berkeleyvision.org/install_apt.html)。默认的是 OpenBlas。不要担心编辑 Makefile.config 或使用 Caffe 的问题。在 Ubuntu 16.04 上尝试这个,并在其上附加依赖包:
sudo apt install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt install --no-install-recommends libboost-all-dev
sudo apt install libopenblas-dev python-numpy
#Add symbolic links for hdf5 library#(not necessary on LinuxMint 18)cd /usr/lib/x86_64-linux-gnu
sudo ln -s libhdf5_serial.so libhdf5.so
sudo ln -s libhdf5_serial_hl.so libhdf5_hl.so
证书
代码(包括训练好的模型)按 GPLv3 授权。Caffe 使用的是 BSD 2 授权。
©本文由机器之心编译,转载请联系本公众号获得授权。
?------------------------------------------------
加入机器之心(全职记者/实习生):hr@almosthuman.cn
投稿或寻求报道:editor@almosthuman.cn
广告&商务合作:bd@almosthuman.cn
